Publications
Peer-reviewed or pre-print publications. Check my Google scholar for the complete list.
(* indicates equal contribution)
2024
-
 Biomedical Signal Processing and Control, 2024
Biomedical Signal Processing and Control, 2024


2023
-
 IEEE Transactions on Robotics (T-RO), 2023
IEEE Transactions on Robotics (T-RO), 2023 -
 In 2023 IEEE International Conference on Intelligent Robots and Systems (IROS), 2023
In 2023 IEEE International Conference on Intelligent Robots and Systems (IROS), 2023


2022
-
 In 2022 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2022
In 2022 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2022 - CRASIn CRAS, Naples, Italy, avril 2022, 2022


2021
-
 In 2021 20th International Conference on Advanced Robotics (ICAR), 2021
In 2021 20th International Conference on Advanced Robotics (ICAR), 2021 -
 In 2021 International Symposium on Medical Robotics (ISMR), 2021
In 2021 International Symposium on Medical Robotics (ISMR), 2021 -
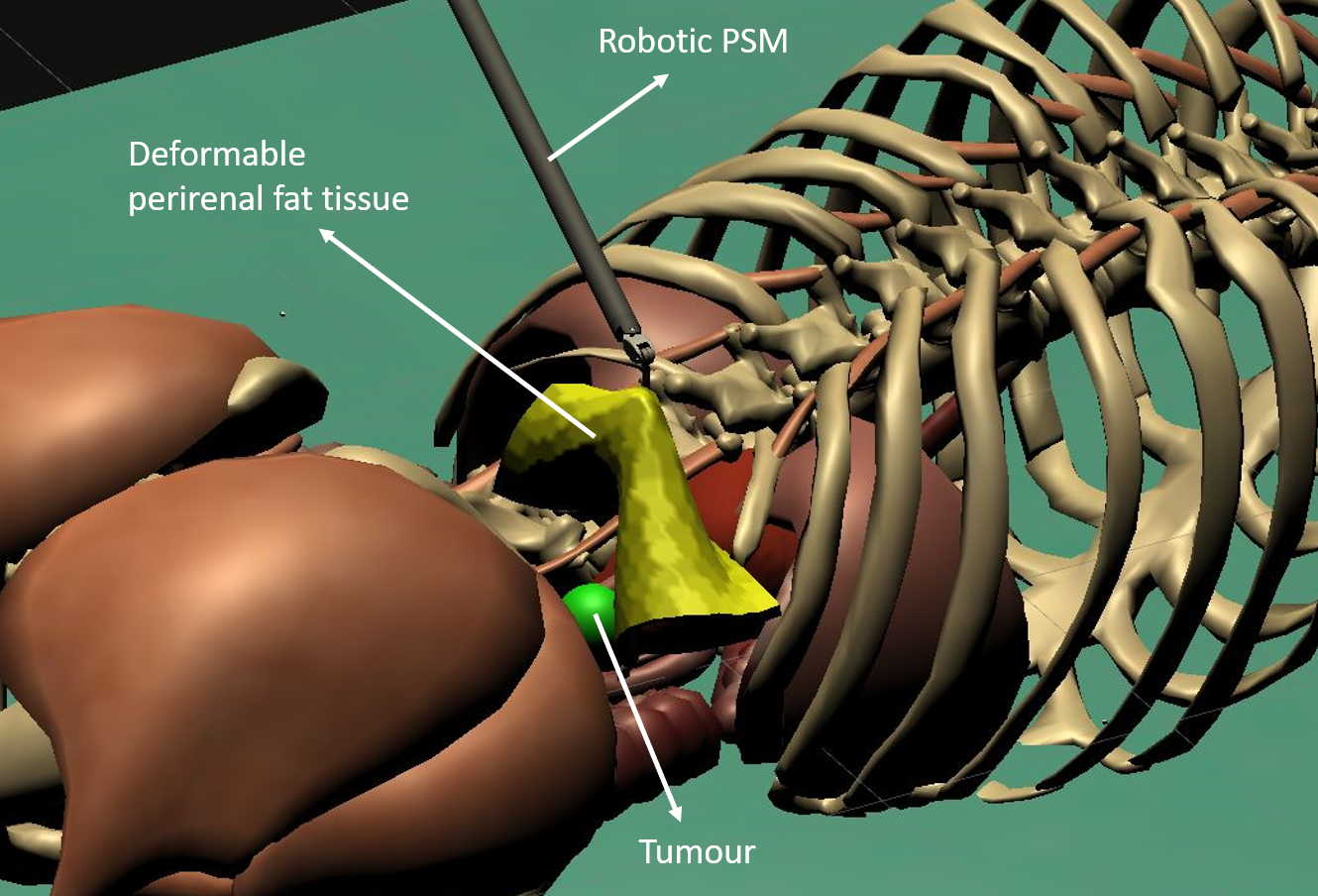 In 2021 IEEE International Conference on Intelligent Robots and Systems (IROS), 2021
In 2021 IEEE International Conference on Intelligent Robots and Systems (IROS), 2021 - ICDLIn 2021 IEEE International Conference on Development and Learning (ICDL), 2021



2020
-
 In 2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2020
In 2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2020 - CRASFramework for soft tissue manipulation and control using Deep Reinforcement LearningIn Proceedings of the 10th Joint Workshop on New Technologies for Computer/Robot Assisted Surgery, 2020
-
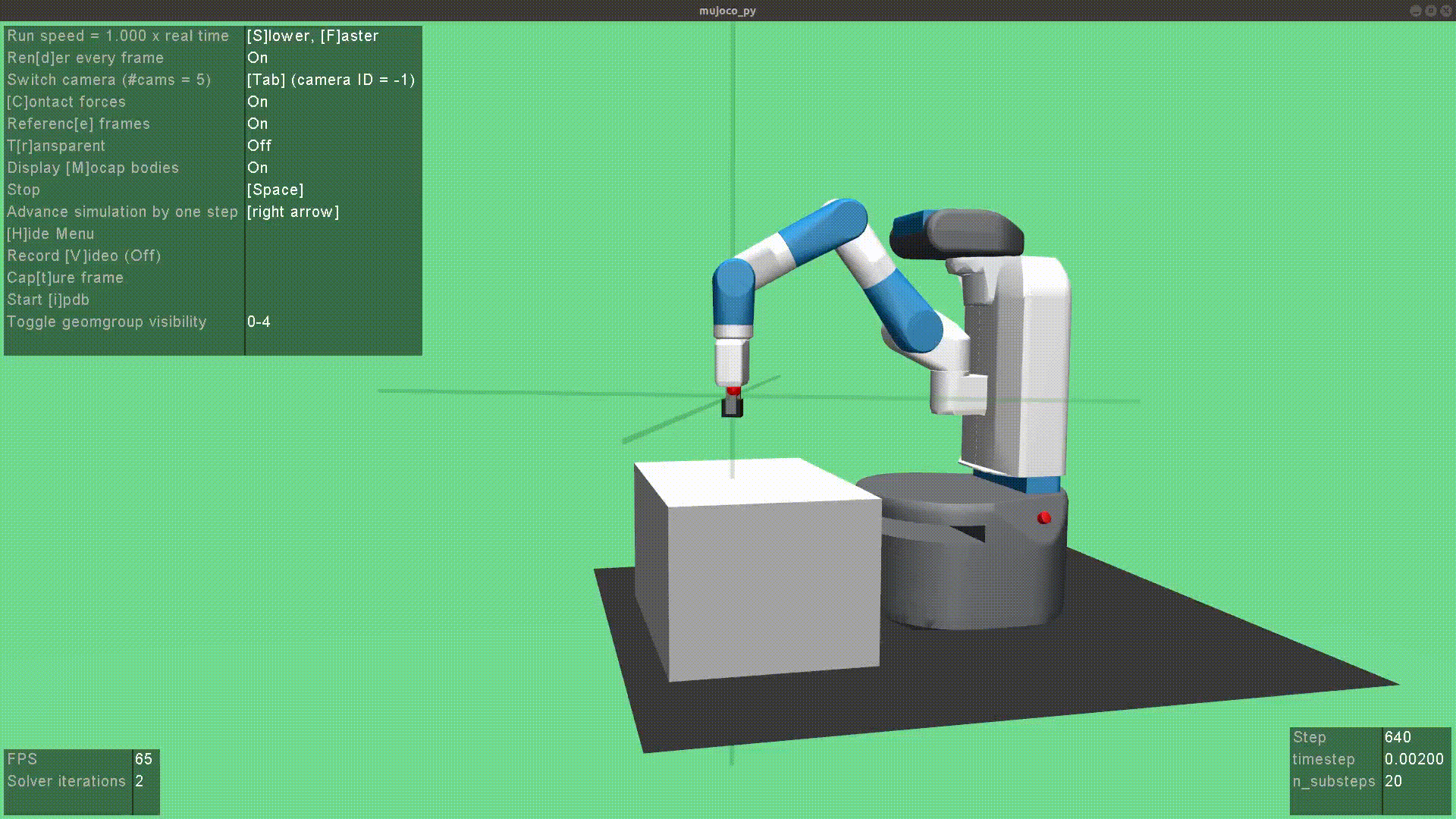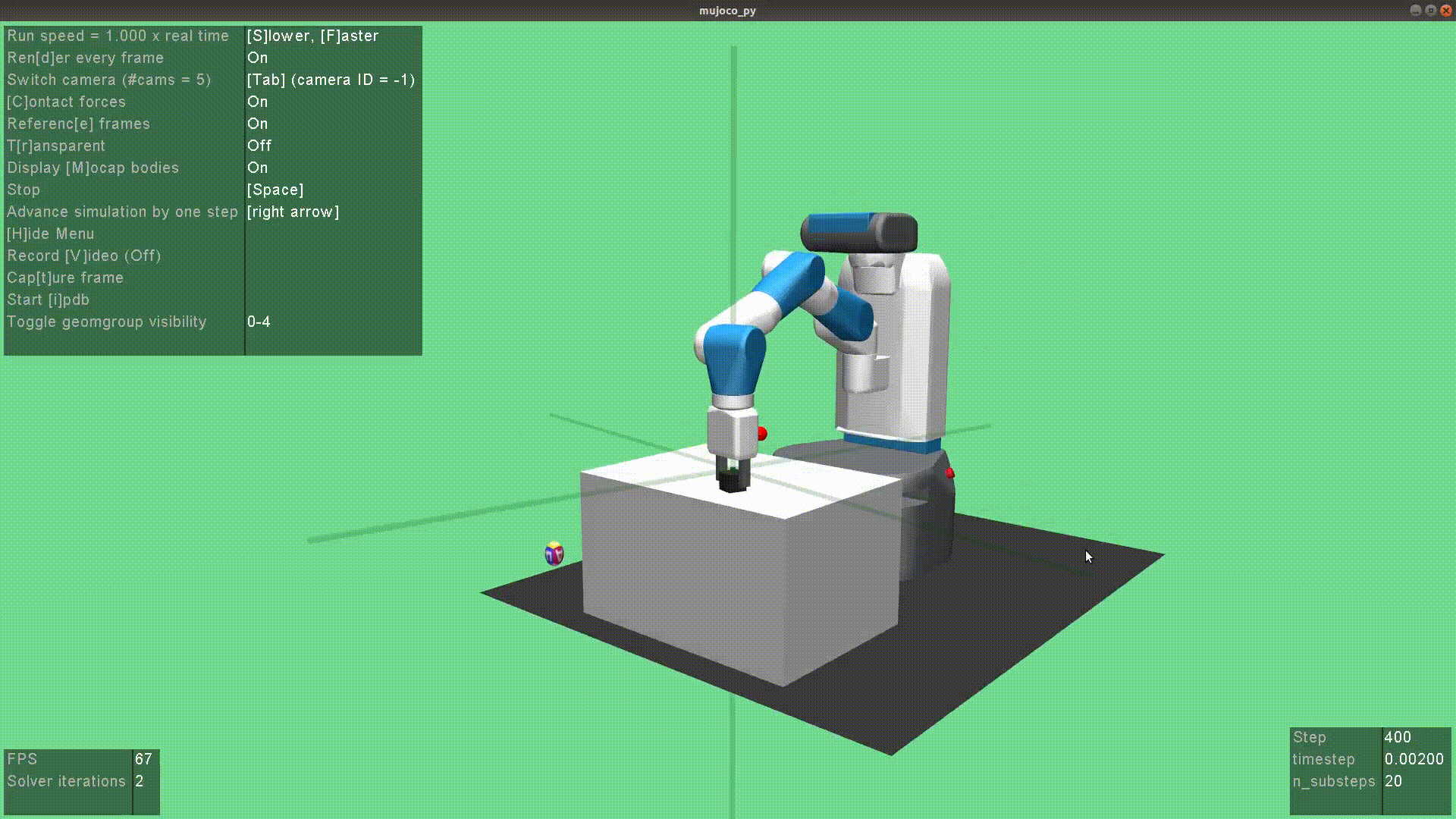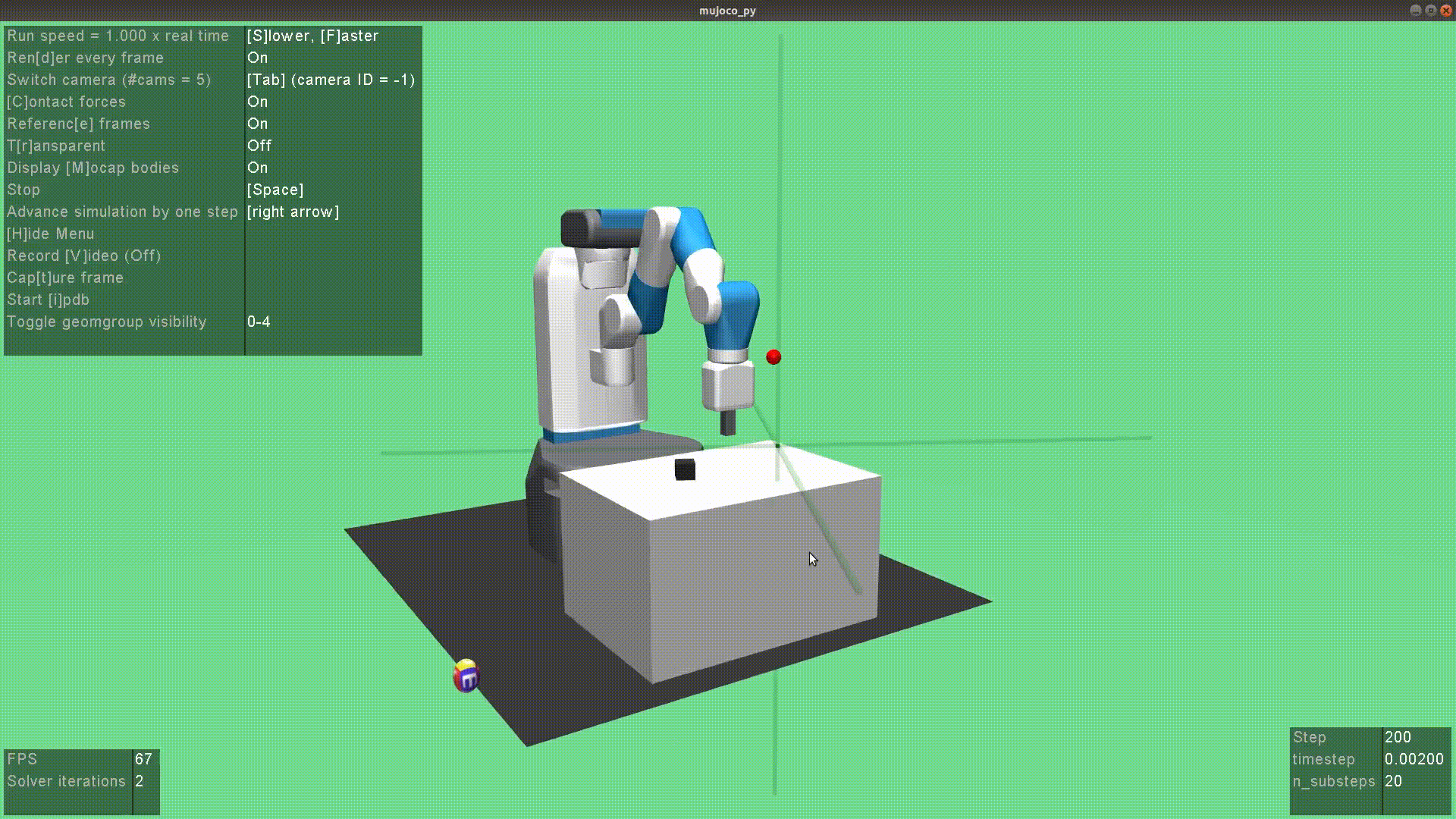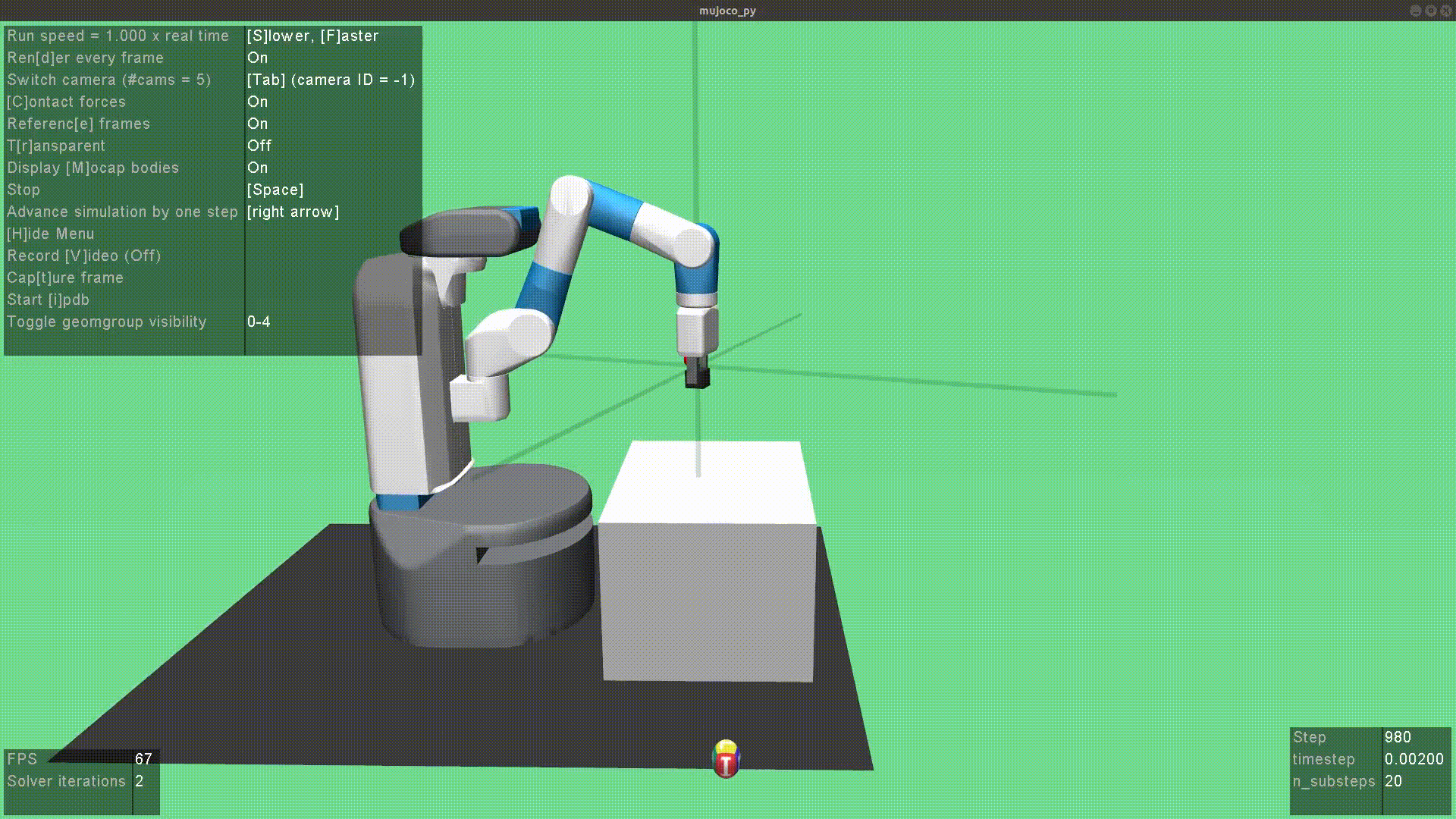 In 2020 IEEE International Conference on Robotics and Automation (ICRA), 2020
In 2020 IEEE International Conference on Robotics and Automation (ICRA), 2020

